Troubleshooting Playbook – Triangulating Issues with Remote Worker Agents
Abstract: As ITOps and security teams are deploying more sensors on user devices to close the data gap of measurements between their remote workers and their data-centers and applications, there has to be a methodical way of isolating and pinpointing user-impacting network and application issues.
How to tackle challenges with Remote Worker Observability
A few weeks ago Stefano Gridelli and Greg Ness wrote a blog discussing the top 4 observability challenges ITOps and security teams encounter when dealing with remote worker observability. Namely, 1) ISPs and VPNs, 2) Distributed/cloud apps, 3) Consumer-grade equipment, 4) Field support.
This week I’d like to take you through a method that is designed to bring out the value of data gathered by remote worker agents/sensors scattered across multiple geographic locations and across multiple ISPs. All of these devices are trying to access different network services, applications, and resources that are sensitive to performance issues and the continuous entropy of today’s networks.
Consider the following diagram. It is a representation of a decision tree, designed to diagnose the nature of a user-impacting issue, based on data reported by multiple remote worker agents testing multiple network resources.
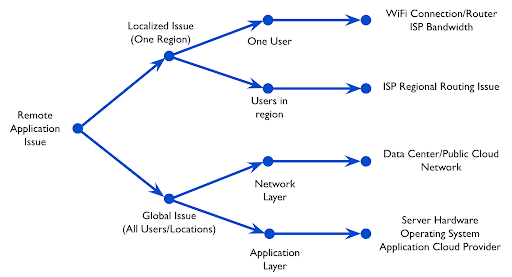
At the root of the decision tree you have a report of a remote application issue, may that be from a user complaint or directly from your monitoring application. The next step is to understand if this is a global issue, affecting every user, or a localized one, pertaining to a certain region, or a certain group of users who share a set of characteristics (e.g on the same ISP of a certain locality).
If the issue is a localized one, then you should further understand if this issue is on a single user or a group of users. If the problem is on a single user, then it is most likely related to the WiFi connectivity or the router, or with the bandwidth available through the user’s ISP. If the problem affects multiple users, then it is most likely related to an ISP Regional Routing Issue.
If the issue is a globalized one, then the distinction would be between that being on the network layer or the application layer. Network layer issues are usually related to Datacenter network equipment, such as firewall rules or router resources. Application layer issues are usually attributed to server hardware or resource availability, or the Application cloud provider itself in the case of SaaS applications.
Case Study: An intermittent Voice/Video quality complaint
A few days ago, one of our Sales Executives was having intermittent voice and video quality issues during a zoom demo call. Fortunately, she was running a NetBeez remote worker agent on her laptop, making it easier to troubleshoot problems with zoom and other applications. The agent was configured to monitor the performance of her home network to various services both towards SaaS applications as well as towards our office network, which goes through a VPN connection.
When we received the complaint we noticed that multiple services on her agent were reporting errors on PING and HTTP tests.
![]() Looking at the historical data we were able to pinpoint the exact time the network was down on Nov 12, 2020 at 1:48pm.
Looking at the historical data we were able to pinpoint the exact time the network was down on Nov 12, 2020 at 1:48pm.
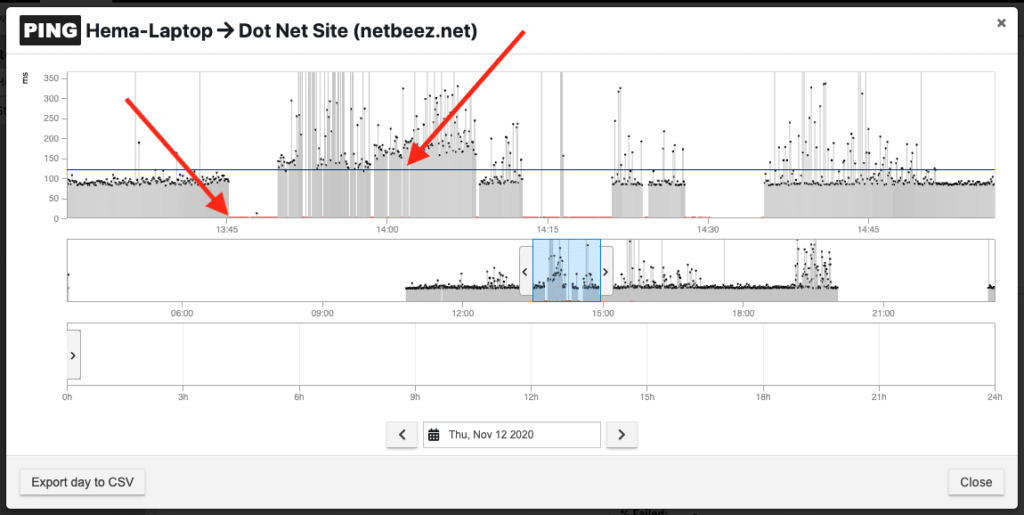
Shortly after the network went down, we noticed that it came back up, but with highly degraded performance, as the round-trip time was increased from what the average was. Unfortunately, we didn’t have other users in the same region and ISP to correlate this observation, but looking into the traceroute data we were able to pinpoint the issue.
We compared the traceroute results from right before the outage, and right after. Before the outage the number of hops to a destination target were 11, but after the outage it was 24 hops.
Before:
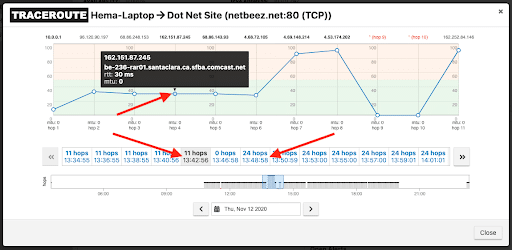
After:
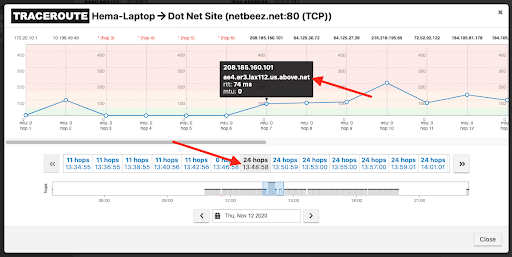
By looking at the results, we were able to quickly identify that under normal circumstances the traffic was going directly through here ISP. After the outage, the traffic was going through a different regional network, making it immediately obvious that the issue has to do with the ISP, and we were able to quickly escalate the issue to be resolved.
Conclusion
“If a tree falls in a forest and no one is around to hear it, does it make a sound?”. Well if you have sensors on every tree in the forest feeding you data, then you can hear all of the sounds. You can understand if an issue is affecting one or all the trees and once you look deeper into the data you’ll be able to discern what is the problem.
Want to learn more? Watch any of our 2020 webinars on network monitoring with Cisco, Extreme, NetBeez customers and remote worker network monitoring.